Often in rigorous mathematics one will see a definition like the following:
Definition
A function 
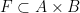
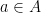
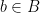
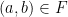
Now this is all well and good but in practice many people (myself included) like to draw a distinction between the graph of a function and the function itself. Often informally one might see an analogy made with a machine that takes input and gives output or something similarly mechanistic. This has a certain sense of dynamism and movement which the rather austere and static graph doesn’t seem to quite capture. Instead of the above I believe most people tend to think of a function as being something that satisfies the following properties:
- A function has a domain and a codomain (this one is arguable depending on the context e.g. in calculus one might not distinguish between a function and its corestriction to a subset of the codomain).
- For each input value from the domain there is a uniquely assigned value in the codomain.
- This information completely characterises the function.
A majority of the time mathematics can get by with a synthetic definition such as this one and not worry about a particular realisation of the concept of function in axiomatic set theory (where everything must be a set) or within any other particular foundations (granted, knowing the cardinality of 
In programming one makes a distinction between a specification and an implementation. A specification describes what a program should do and possibly some properties it should have e.g. the program should sort a list of numbers and be at worst 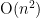
I believe it would be useful for mathematics to more conspicuously observe this distinction. As another example let us consider a well-known sticking point – the definition of a product. In set theory we say the product of two sets 

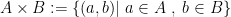
That isn’t so weird until we ask what the definition of the ordered pair 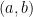

Once again there is nothing wrong with this definition. It is, in fact, an ingenious way to encode a unique set for each 

Category theory instead offers a specification: 
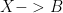

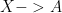

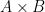
Given this we might think of category theory as a kind of ‘specification language’ for mathematics. We define objects by (universal) properties they must satisfy – usually as limits and colimits (or related concepts) – but don’t offer a particular implementation. This might lead us to worry about the specification being underdetermined but luckily it is a standard result that a limit or colimit is unique up to unique isomorphism. A topologist might prefer to say that the space of objects satisfying a universal property is contractible or to be more precise is a contractible groupoid.
This might lead one to wonder then, are there better implementation languages for the foundations of mathematics? That is, languages which are closer to our specification language (we might also be led to wonder about whether 
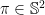
One fruitful idea, originating with Lawvere, for such a foundations is simply category theory itself. In such a setting we can then go on to give a structural account of the theory of sets (as a topos with function extensionality, a natural numbers object and satisfying the axiom of choice; all of which can be phrased in purely categorical terms).
Alternatively univalent foundations promises a new language whereby there is no distinction between a contractible groupoid of choices and a unique choice. This is a language that is constructive by default and in some sense takes homotopy types as a primitive notion (i.e. we think of the primitive typing relation 

